

𝘚𝘭𝘰𝘸 𝘣𝘶𝘵 𝘴𝘵𝘦𝘢𝘥𝘺
GPT-1, GPT-2, GPT-3 이해하기 본문
어느덧 인공지능의 대명사가 된 GPT..
OpenAI의 GPT의 초기 모델이었던 GPT-1, GPT-2, GPT-3를 이제야 읽고 정리해보았다.
GPT-1, 2, 3 논문 정리
GPT-1: Improving Language Understanding by Generative Pre-Training
GPT-2: Language Models are Unsupervised Multitask Learners
GPT-3: Language Models are Few-Shot Learners
GPT란?
Generative Pre-Trained Transformer로, 말 그대로
사전 훈련된 Transformer 모델 기반 언어 생성 모델이다.
즉, GPT-1, 2, 3 그 외 모든 GPT 모델은 Decoder-only 구조로, Transformer가 sequence를 입력받아 이해한 뒤(encoder) sequence를 생성하는/출력하는(decoder) trasnduction task를 수행하는 모델이라면,
GPT는 encoder layer 없이 프롬프트를 입력받아 그 뒤의 sequence들을 생성하는 모델이다.
이러한 GPT 논문은 1, 2, 3까지 모델이 나오는 동안 두 개의 공통적인 문제 해결을 위해 지속적으로 발전되어왔다.
1. Label 된 데이터의 부족
아무리 텍스트 데이터의 양이 방대하다 하여도 다양한 NLP task 별 모델 학습을 위해 필요한 다량의 label 된 데이터를 확보하기는 어렵다. 모델이 '잘' 학습되기 위해서는 최소 천 ~ 십만 단위의 데이터가 필요한데, 사람이 일일히 라벨링한 몇 만개의 데이터셋을 구하는 것은 상당히 비용 집약적이다. 이를 극복하기 위해 기존 모델들은 다량의 unlabeled data를 활용한 unsupervised pre-training 과정을 통해 모델의 일반화 능력을 극대화 시키고자 하였다.
2. 더더더 범용적인 모델
그렇게 pre-training > fine-tuning 기반의 전이 학습 프레임워크를 기반으로 제안되었던 것이 GPT-1인데, 그 fine-tuning 과정조차도 데이터에 대한 비용이 부담스럽다고 제안되었던 것이 GPT-2 이후의 모델이다. Fine-tuning 과정도 어쨌든 supervised-learning 기반이므로, 원하는 task에 적합한 label된 데이터가 필요하다. 따라서, GPT-2 이후에는 더욱 일반화된 모델을 만들기 위해 few-shot learning이나 zero-shot learning 프레임워크를 씌워 모델 구조나 파라미터의 수정 없이 사전 훈련 후 바로 다양한 문제에 적용할 수 있는 모델을 제안하고자 하였다.
GPT-1, 2, 3의 요약 및 발전 방향 비교
우리는 우리에게 새로운 아이디어가 필요하다고 생각했지만,
규모를 키우는 것만으로도 우리가 원하는 바를 구현할 수 있었다.

GPT-1; Improving Language Understanding by Generative Pre-Training
등장 배경
다양한 NLP 분야의 논문에도 나와있는 말이지만, 자연어를 이해하는 task는 굉장히 다양하다. Textual entailment, question-answering, semantic simliarity assessment, 등등등.. 마찬가지로 plain 언어 데이터는 어딜 가나 흔하다. 당장 웹 하나만 찍어 긁어오기만 해도 방대한 양의 데이터를 구할 수 있다.
그러나 Task 별로 모델을 학습하기 위해 필요한 'label이 있는' 데이터는 흔치 않다.
그렇기 때문에 label 되지 않은 충분한 양의 텍스트 데이터를 활용한 pre-train 된 생성 모델이 필요하다. 따라서 GPT-1에서는 비지도 학습 기반의 pre-training 단계와, task 별 지도 학습 기반 fine-tuning 단계를 거쳐 학습을 진행하는 semi-supervised learning 방식을 사용한다.
모델 구조
GPT 모델은 전반적으로 Transformer의 디코더 구조를 활용한다. Attention 메커니즘을 통해 장기 의존성 문제를 효과적으로 극복하고 다양한 태스크에 적용할 수 있기 때문에, 전이 학습을 활용하여 강력하고 견고한 성능을 달성할 수 있기 때문이다. GPT는 masked self-attention과 position-wise feed-forward의 두 개 sub-layer로 구성되어 자기회귀적(auto-regressive) 방식을 기반으로 이전 토큰 정보만을 활용하여 다음 토큰을 예측한다.

학습 방법
비지도 학습 기반의 사전 학습 단계에서는 다량의 말뭉치 데이터로부터 언어의 복잡한 패턴 능력을 학습하는 능력을 가진 모델을 학습하고,
지도학습 기반 fine-tuning 단계에서는 task별 적합한 모델로 tuning하는 과정을 거쳐 원하는 토큰들을 예측하여 문제를 해결한다.
Unsupervised pre-training
$\mathcal U=\{u_1, \dots, u_n \}$ 이 label 정보가 없는 말뭉치 토큰들이라고 할 때, 아래의 가능도 수식을 최대화하는 언어 모델 설계하는 것이 pre-training 단계의 목표이다.
$$ L_1(\mathcal U)=\sum_i\log P(u_i|u_{i-k}, \dots, u_{i-1};\Theta) $$
이 때, $k$는 context window의 크기이고 P는 파라미터집합 $\Theta$를 사용하여 모델링되는 신경망의 조건부 확률이다.
위 식의 의미를 해석하자면,
최종적인 목표는 $\mathcal U=\{u_1, \dots, u_n \}$의 각 토큰 $u_i$를 이전 k개의 토큰을 조건으로 예측하는 확률의 log likelihood를 최대화 하는 것이다. 즉, i번째 토큰은 (i-k)번째 토큰부터 (i-1)번째 토큰을 기반으로 학습하였을때, 모델이 조건부 확률 분포를 계산하고, 그 분포에서 가장 높은 확률을 가진 토큰이 예측된다. 이는 자동회귀 방식의 maximum likelihood estimation(최대 우도 추정) 목적 함수에 해당한다.
위 수식을 통해 학습을 할 때, MLE 통해 조건부확률을 최대화하는 방식으로 모델 파라미터 Θ를 직접 학습하게 되는데, 이 때 모델은 문맥 정보를 학습하고, 언어의 통계적 패턴과 구조를 내재화하게 된다. Context window인 k는 한 토큰 예측시 고려하는 이전 토큰의 개수로, 모델이 문맥을 얼마나 멀리까지 반영할 것인지 결정한다. 이를 통해 pre-training 단계에서는 범용적이고 강력한 표현을 학습하게 된다.
Supervised fine-tuning
위의 MLE 수식으로부터 모델을 학습하고 나면, 학습된 파라미터들을 기반으로 supervised target task 진행하여 모델 학습을 진행한다. $\mathcal C$이 label된 데이터셋일 때, 각 instance는 시퀀스들의 입력 토큰 $x^1,\dots,x^m$ 으로 구성, $y$는 하나의 시퀀스에 대응되는 label을 의미한다.
입력값은 Transformer의 마지막 레이어에서 나온 최종 hidden state 값($h_l^m$, 각 토큰 또는 전체 시퀀스에 대해 학습한 최종 문맥적 표현)을 의미한다. 이 때 $l$은 layer 블록 번호, $m$은 토큰 위치를 의미하고, 최종 hidden state는 마지막 선형 출력 Layer에서 $W_y$ 파라미터와 연산되어 $y$값 예측에 사용된다.
$$ P(y|x^1, \dots,x^m)=\text{softmax}(h_l^mW_y) $$
이를 수식으로 정리하면 위와 같은데, 입력 토큰에 의해 결정되는 label 정보 $y$는 $\text{softmax}(h_l^mW_y)$ 를 통해 연산 가능하다.
최종적으로 지도 학습 기반 미세 조정 단계에서 최대화해야하는 목적 함수는 다음과 같다.
$$ L_2(\mathcal C)=\sum_{(x,y)}\log P(y|x^1, \dots, x^m) $$
두 단계의 학습을 고려한 최종적인 목적함수는 다음과 같다.
$$ L_3(\mathcal C)=L_2(\mathcal C)+\lambda\ * \ L_1(\mathcal C) $$
- $L_1(\mathcal U)=\sum_i\log P(u_i|u_{i-k}, \dots, u_{i-1};\Theta)$
- $L_2(\mathcal C)=\sum_{(x,y)}\log P(y|x^1, \dots, x^m)$
입력 데이터 형식
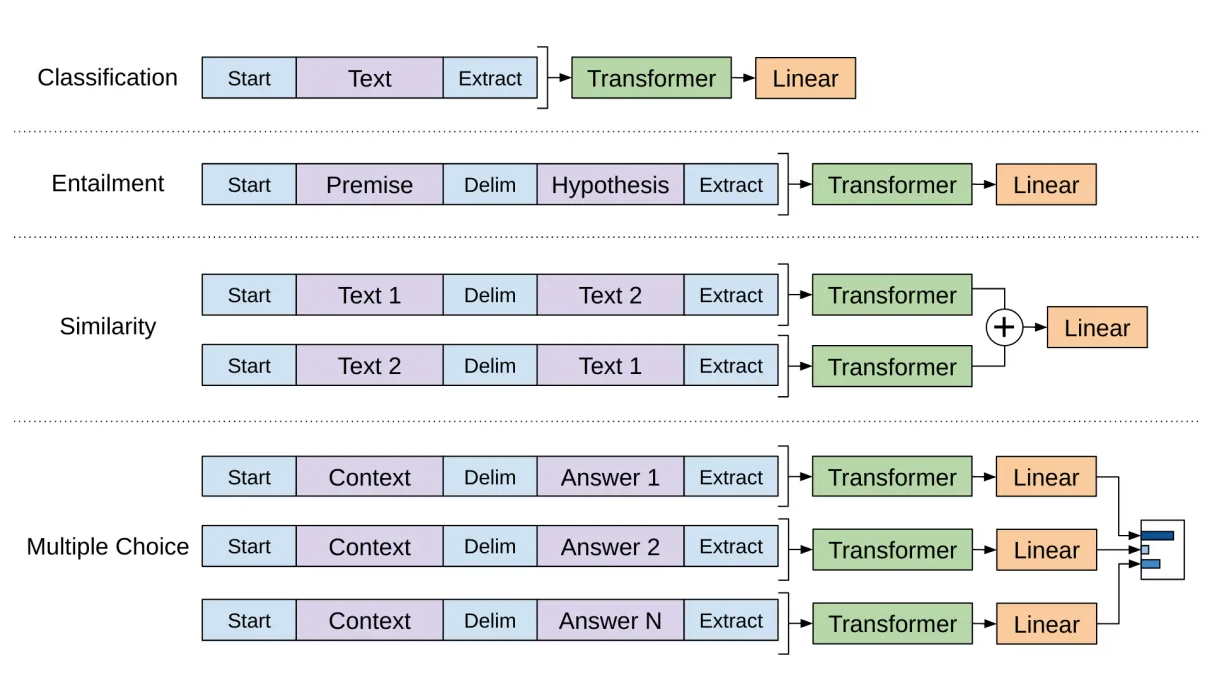
GPT의 경우, 하나의 언어 모델이 모델 구조의 수정 없이 다양한 문제를 해결하기 위해 각 task별 입력 문장들을 단일 sequence로 표현한다. 따라서, 각 task별로 위와 같이 다양한 형태로 문장 구조를 수정하여 입력 sequence로 사용한다.
Text entailment
전제(premise, $p$) 문장과 가설(hypothesis, $h$) 문장을 delimiter token($)을 사이에 두고 concat
문장 유사도
두 문장 사이에 전후관계는 없기 때문에 두가지 경우의 수를 모두 포함(A$B, B$A), 각각 독립적으로 처리하고 마지막에 두 개의 문장 결합하여 최종 표현 $h^m_l$ 생성
질의응답 / 상식 추론
Context document $z$, 질문 $q$, 가능한 답안 목록 $\{a_k\}$ 주어짐
document text와 질문들을 각 가능한 답변들과 concat하고, 그 사이 delimiter token 추가해서 $[z;q;\$;a_k]$ 모양의 입력 시퀀스 생성
각각의 시퀀스들은 독립적으로 처리된 후 마지막에 softmax 적용되어 가능한 답변들로부터 출력 분포 생성 → 정답인 문장이 가장 높은 확률을 가지도록 학습됨.
GPT-2; Language Models are Unsupervised Multitask Learners
등장 배경
기존 ML 모델들은 single-task learning이라는 문제가 존재한다. 한 도메인의 데이터셋에 대해 하나의 task만 처리할 수 있도록 훈련하는 것은 결국 일반화 능력의 부족으로 이어진다. 그에 따라 현재 모델들로 다양한 task에 적용할 수 있는 시스템을 만들기 위해서는 보다 넓은 도메인의 데이터와 넓은(broad) 학습이 필요하다. NLP 문제중에서는 GLUE, decaNLP와 같은 데이터셋이 대표적으로 다양한 task를 해결하기 위해 제안된 데이터셋이다.
서론을 보면 알겠지만, multi-task learning으로 접근하여 이전 모델보다 더욱 더 범용적인 언어모델을 만들고자 제안된 것이 GPT-2 이다.
NLP와 multi-tasking?
이전 상황에서 일반화 성능이 높은 모델을 유도하기 위해서는 큰 데이터셋이 필요하다. 그리고 언어 모델에서 가장 많이 사용되는 방식은 비지도 학습 기반 사전 학습 + 지도학습 기반 미세 조정 단계의 학습 프레임워크가 가장 많이 사용된다(GPT-1과 같은 경우). 그러나 어쨌든 이러한 방식들도 지도학습 훈련 방식이 필요하고, 만약 label된 데이터가 부족하다면 좋은 성능의 모델을 달성하기가 어려울 것이다.
그에 따라 GPT-2에서부터는 언어 모델의 '일반화 능력'에 조금 더 초점을 맞춰 언어 모델과 zero-shot learning을 접목하여 fine-tuning 단계의 비중을 줄이고자 하였다.
방법론
언어 모델은 주로 입력 길이가 정해지지 않은 토큰들로 구성된 문장들로부터 분포를 추정하는 방식으로 학습이 진행된다(MLE). 각각의 문장들은 정해진 '연속적 순서'가 있기 때문에, 이 토큰들 간 결합 확률은 조건부 확률 연산의 곱으로 분해하여 계산 하는것이 일반적이다.
$$ p(x)=\prod_{i=1}^np(s_n|s_1,\dots,s_{n-1}) $$
뭔소리냐면 transformer같은 모델들이 위와 같은 수식을 통해 조건부 확률 연산하여 확률 분포 중 최대 확률인 토큰들을 연달아 연산하는 방법으로 NLP task 처리들에 있어 대단한 성능 개선을 이루어냈다.
Single task learning에서는 $p(output|input)$ 를 추정하는 형태로 학습이 진행된다면, multi-task learning에서는 입력값 뿐 아니라 task까지 조건에 고려되어야 하기 때문에, $p(output|input, task)$ 와 같은 형태로 모델이 정의되어야 한다.(이건 그냥 multi-task learning의 일반적인 공식이다.)
그리고 언어는 task, input, ouput을 모두 일련의 토큰/심볼로 지정할 수 있는 유연한 방법을 제공한다.
예시)
영어 -> 프랑스어로 번역하는 번역 task의 경우, (task: translate to french, input: English text, output: French text)
질의응답의 경우, (task: answer the question, input: document, output: answer)
언어 모델은 정확히 어떤 토큰이 예측되어야 하는 토큰인지? 명시적으로 지정하는 지도학습 정보 없이도 원칙적으로는 학습을 할 수 있다.(언어에는 정해진 정답이 없으므로). 다시 말하면, 단순히 '텍스트 자체' 만을 보고 그 내부의 패턴을 학습할 수 있다. 즉, 언어에 대해 명시적인 “정답”이 주어지지 않아도, 모델은 텍스트의 확률 분포를 추정함으로써 자연스럽게 언어 패턴을 익히게 된다.
따라서 GPT-2에서는 충분한 학습 역량/범용성을 갖춘 언어 모델이 자연어 시퀀스 안에 내제된 다양한 task를 자동으로 추론하고 수행하는 방법을 익히게 되면, 어떤 문제인지 상관 없이 더 좋은 예측 성능을 달성할 수 있다. 그렇게 되면 궁극적으로 multi-task learning을 수행하는 것과 같은 의미가 된다.
입력 데이터
GPT-2에서는 WebText라는 데이터셋을 새로 구축하였다.
WebText는 레딧(Reddit)에서 3개 이상 추천(karma) 받은 게시글들을 수집하였다. 이 추천이 무슨 의미냐, 유저들이 직접 남긴 지표이기 때문에 해당 포스트가 흥미롭거나, 유익하거나, 아니면 최소 재미있는 글이라는 의미가 된다. 그에 따라 매우 잘 정제된 데이터셋으로 볼 수 있다고 한다.
모델
GPT-1과 거의 동일한 형태이지만, 몇가지가 수정되었다.
Layer normalization
각 sub-block의 입력층으로 이동하였다. 이를 통해 ResNet의 구조와 거의 유사한 형태를 띄게 되었다.
최종 self-attention block 이후에 layer normalization 추가
모델의 깊이가 깊어질수록 residual 연결 경로를 통해 누적되는 효과를 고려하여 가중치 초기화 방식을 수정하였다. 즉, 깊은 네트워크에서 residual 연결들이 여러번 누적되면서 발생할 수 있는 스케일링 문제(e.g. 기우리 소실/폭발)를 완화하기 위해 초기화 값을 조정하게 되었다.
초기화 단계에서 residual layer의 가중치를 $1/\sqrt N$ 으로 수정
이 때, N은 residual layer의 수이다.
하이퍼파라미터의 확대
사용 가능한 단어의 수를 50,257개로 확장하였다.
Context size는 512에서 1,024 토큰으로 증가시켰다.
더 큰 batch size(512)를 사용하였다.
이를 통해 GPT-2는 기존 GPT-1의 아키텍처를 크게 바꾸지 않는 선에서 데이트와 학습 절차를 확장하여 더욱 강력하고 범용적인 언어 모델을 구현하게 되었다.
GPT-3; Language Models are Few-Shot Learners
연구 배경
기존의 fine-tuning 기반 언어모델로부터 모델의 파라미터 수를 확장(175B)시키고, fine-tuning 단계를 건너뛴 상태로 3가지 학습 프레임워크에 접목하여 범용적인 언어모델을 설계하였다.
GPT-3에서는 보다 일반화 능력이 큰 모델을 설계하기 위해
- 모델의 파라미터 수를 증가시키면 더 다양한 skill과 task를 학습할 수 있다고 보았다.
- 모델의 meta-learning 활용; 언어 모델이 광범위한 skill과 패턴 인식 능력을 개발하여 그 능력을 추론에 활용하여 원하는 task에 빠른 적응이 가능하도록 했다.
두 가지의 가설을 세웠고,
FSL/OSL/ZSL 의 세가지 관점에서 언어 모델을 해석하고자 하였다.
+ FSL/OSL/ZSL?
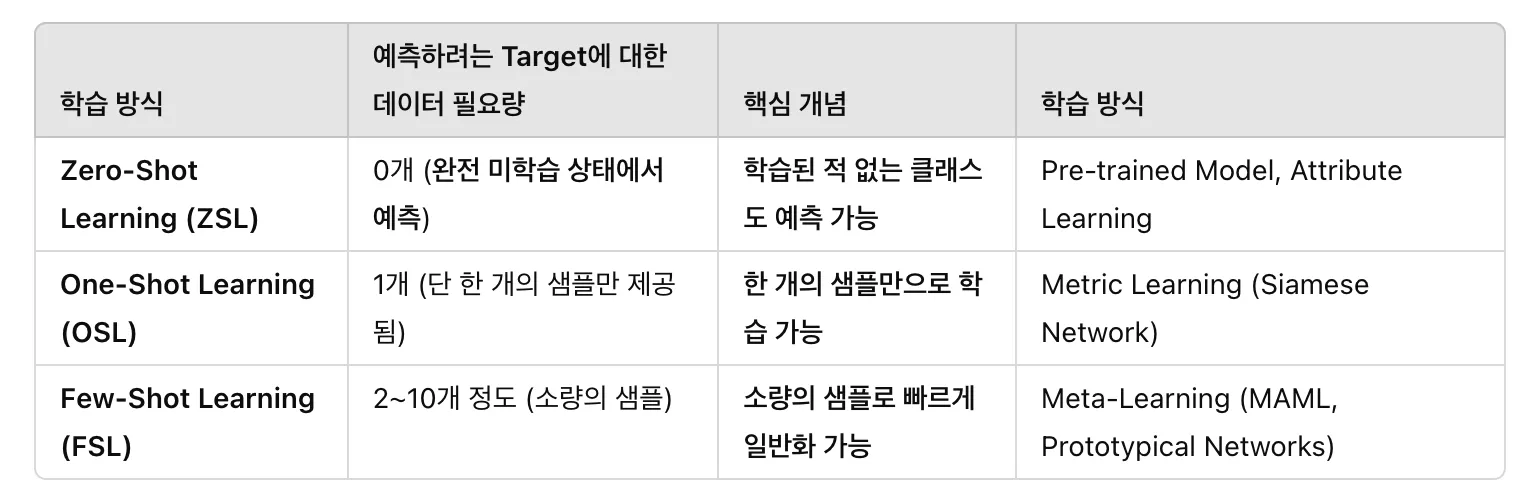
Zero-shot learning: 학습된 데이터가 아닌 unknown label이 들어왔을 때 그 데이터를 분류(그 외 다양한 task들 처리)할 수 있는 능력을 가진 모델
FSL(few-shot learning)과 OSL(one-shot learning)은 데이터의 양이 한정되어있을때도 학습을 통해 task를 처리할 수 있는 일반화 능력이 뛰어난 모델
- fsl에서 더 extreme한 상황이 osl
· FSL: label 별 극히 일부의 데이터셋만 필요
· OSL: label 별 1개의 데이터셋만 사용
방법론
기본 사전학습 방식은 GPT-2와 모델, 데이터, 훈련 방식은 유사하다. 다만 제안하였던 목적에 맞게 모델크기, 데이터셋, task 다양성 등을 조금 확대하였다.
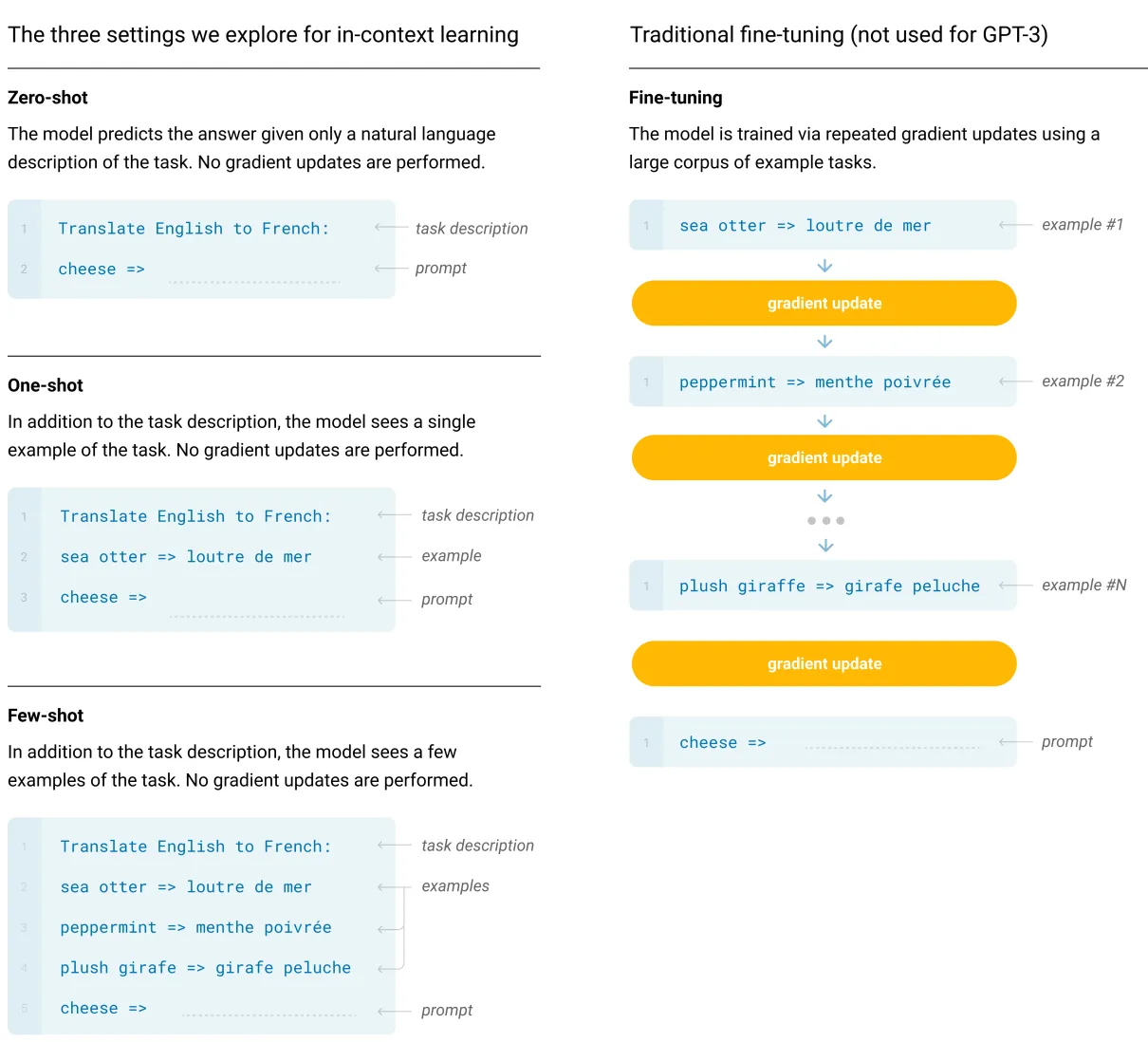
in-context learning의 쓰임새도 GPT-2와 유사하지만, 해당 작업에서는 컨텍스트 내에서 학습을 위한 다양한 설정을 체계적으로 탐색한다.
→ GPT-2 이전의 in-context learning vs GPT-3에서 제안하는 in-context learing
- GPT-2 이전 모델: 제한적인 맥락 활용으로, 주어진 데이터에 대해 단순히 패턴 매칭하는 수준에 가까웠음.
- GPT-3: 대규모 언어 모델링을 통해, 문맥 내 예시 몇 개만으로도 새로운 태스크를 해결할 수 있는 “in-context learning” 능력을 크게 끌어올림. 수십~수백억 단위의 파라미터를 지닌 초거대 언어 모델 최초 제안
- 이로써 GPT-3의 in-context learning은 이전 세대 모델들과 비교했을 때, 파라미터 수의 급증과 광범위한 학습으로 인해 “문맥에서 규칙을 즉석에서 습득하고 적용하는” 모습에 훨씬 가까워졌다는 점에서 큰 차별점이 존재한다.
GPT-3을 평가할 수 있는 원칙/항목
Fine-Tuning
Fine-Tuning은 일반화된 방법으로 굳어져있는 상태다. 즉, 기존 모델들은 fine-tuning 단계에서 일반적으로 1,000 ~ 100,000+개의 label된 example들 사용한다. Fine-tuning의 장점은 다양한 벤치마크 데이터셋에서 강력한 성능을 자랑한다는 것인데, 매 task마다 저 정도 규모의 거대 데이터셋이 필요하고, 일반화 능력이 약해 분포 외 데이터(out-of-distribution)에 대해 좋은 성능을 보이지 않는다. 또한, 훈련 데이터로부터 거짓된 feature이 학습될 우려로 인해 인간 성능과 비교하기 어렵다.
- spurious features: 모델이 실제 태스크와 관련 없는, 우연히 데이터에 나타난 패턴이나 상관관계를 학습할 위험이 있다는 것을 의미
→ 따라서 본 논문에서는 GPT-3를 fine-tuning하지는 않으나, 나중의 학습 방향성을 위해 fine-tuning 될 수는 있음
“Task-agnostic” : 특정 태스크에 맞게 조정되지 않은, 일반적인 모델의 성능 의미. GPT-3은 기존의 언어모델에서 보이는 pre-trainig → task-specific fine-tuning 과정이 아닌, pre-train 단계의 일반화 능력과 in-context learning 을 기반으로 다양한 태스크를 수행할 수 있음 보여주고자 함. 이를 통해 얼마나 다양한 task에 대해 ‘범용적인 성능’을 발휘하는지를 측정
모델
모델 구조 자체는 GPT-2와 매우 유사하다. GPT-2에서 제안되었던 초기화 방법 수정, input단에서 layer normalization 진행하는 pre-normalization 진행, reversible tokenization(de-tokenization)은 동일하다는 의미이다.
단, 일반적으로 Transformer의 attention은 “dense attention”(모든 토큰이 서로에게 주의를 기울이는 방식)을 사용하는 반면, GPT-3에서는 일부 레이어가 “locally banded sparse attention”(인접한, 또는 국소적인 토큰들끼리만 주의를 기울이는, 희소한 패턴)와 dense attention을 번갈아 사용함으로써 계산 효율성을 높였다.(Sparse Transformer에서 제안된 방식)
모델의 크기에 따른 성능을 증명하기 위해 파라미터 수를 125M ~ 175B까지 다양하게 한 8개의 모델을 제안하였다.
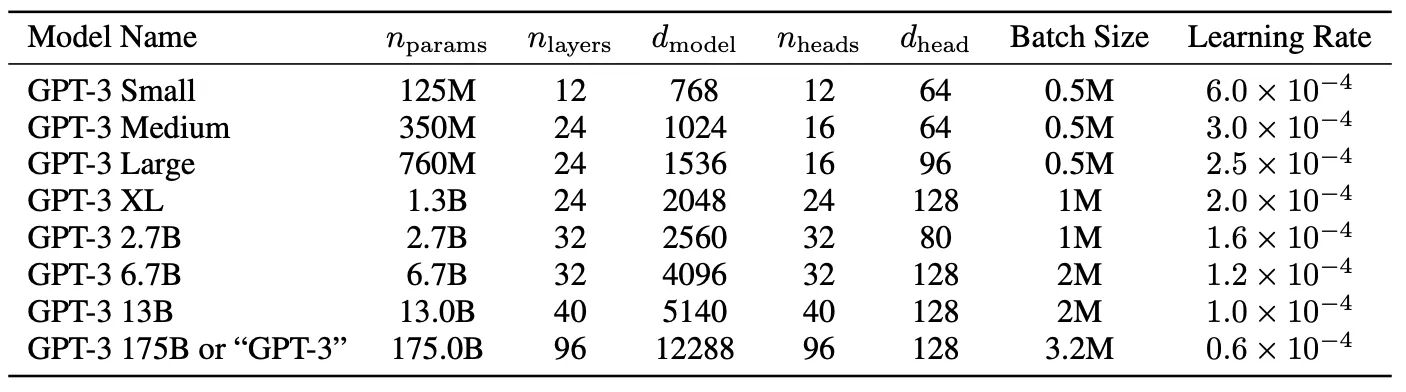
→ 여기서 175B짜리 파라미터를 가진 모델을 GPT-3 이라고 정의
- $n_{layer}$는 layer의 전체 수
- $d_{model}$은 각 bottleneck layer 내 unit의 수(feed forward layer 수는 늘 $d_{model}$의 4배)
- d_{head}는 attention head의 수
- 모든 모델들은 $n_{ctx}$=2048 토큰의 context window 사용
'machine learning' 카테고리의 다른 글
| [LLM] LangChain과 RAG을 활용한 간단한 LLM 기반 챗봇 구현하기 (1) | 2025.03.26 |
|---|---|
| [LLM] LLM의 파라미터, temperature 이해하기 + temperature 설정값 별 답변 확인하기 (0) | 2025.03.14 |
| Attention Is All You Need - Transformer 논문 정리 (0) | 2025.03.04 |
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - BERT 바닥까지 이해하기 (1) | 2025.02.24 |
| A Tutorial on Spectral Clustering - 스펙트럴 클러스터링 (1) | 2023.03.21 |



