
𝘚𝘭𝘰𝘸 𝘣𝘶𝘵 𝘴𝘵𝘦𝘢𝘥𝘺
[LLM] 화상회의 중 STT to TTS 수행하는 시스템 설계 - 1. OpenAI API 'Whisper-1' 활용하여 실시간 STT 구현 본문
[LLM] 화상회의 중 STT to TTS 수행하는 시스템 설계 - 1. OpenAI API 'Whisper-1' 활용하여 실시간 STT 구현
.23 2025. 4. 18. 02:17🗣️ STT?
Speech-To-Text 로, 음성을 텍스트로 변환하는 작업이다.
그걸 누가모릅니까
'본사와 현지 공장 간 트러블 처리 지원 시스템' 중 화상회의 동안의 실시간 STT - 번역 - TTS 파이프라인 설계와 구현을 담당하게 되었는데, (사실 STT 재미있어보여서 내가 하고싶다고 자원함) 그 중 '실시간 STT 시스템'부터 작게 구현해보고자 간단한(코드1823641줄짜리) 프로그램을 설계하게 되었다.
사용 모델
현재 듣고 있는 교육에서 OpenAI API를 사용할 수 있도록 key를 제공해줬기 때문에(스칼라 짱), stt모델 중에서도 토큰 효율적이면서 꽤 예전에 나와 코딩 참고 자료가 많은 'whisper-1'을 사용하게 되었다.
🔗 Whisper-1 공식 API 문서: https://platform.openai.com/docs/models/whisper-1
Google, 파파고, AWS 등에서 STT를 위한 다양한 API를 지원하는걸 알고는 있었고,
OpenAI 모델 중에서도 비교적 최근에 나온 'GPT-4o-Audio' 등 다른 팀들한테 이것저것 주워들은 것은 많은데..
아무튼 OpenAI API 맘껏 쓰라고 떠먹여주는것과 다름 없는 환경을 최대한 활용하고 싶기도 하고,
'다국어지원' + '실시간성' + '그닥 양호하지 않은 로컬 테스트 환경' 을 모두 고려하여
가벼운 오픈소스 모델 아니면 주어진 환경을 최대한 활용할 수 있는 OpenAI API 모델 중 더 잘 되는걸 쓰고자 했다.
그러나..
GPT-4o-Audio는 우선 토큰이 말도 안되게 비쌌다.

양심에 찔림👉👈
opensource whisper https://github.com/openai/whisper
또한 실시간성을 고려하여 오픈소스 whisper 모델을 사용하려고 했더니 'small'부터는 느리고 + 컴퓨터가 터지려하고(M1 학대 ㅜㅜ) 'base' 는 성능이 너무 떨어졌다.

프로젝트 중간에 실제로 whisper base모델을 활용한 stt to tts 실습도 진행한 적이 있었는데...


이건 집에서 조용할때 테스트해본거고..
소음이 어느정도 있는 교육환경에서 테스트 해볼때는 한글로 번역이 안되고 이상한 언어로 튀어버리더라
또다른 옵션으로 경량화된 버전인 faster_whisper도 있었으나..
GPU가 없어서 그런가 API 쓰는거보다 더 느렸다.(30초정도) + 진짜 노트북 터지는 줄 알았음.

이딴게 STT?
그나마 사람다운 말을 뽑아주던게 API였기 때문에 .. 결국 Whisper-1 승.

목적
해당 프로젝트 자체가 화상회의에서 진행되는 것이기 때문에, 화상회의에서 발생할 수 있는 제약사항을 고려한 STT 시스템 구현이 필요했다.
화상회의이기 때문에, 무엇보다 '길이와 상관 없는' 실시간성이 중요하다.
그 이후 진행될 번역과 TTS 작업의 latency를 생각했을 때 말이 다 끝난 후 전체 문장을 서버로 전달하는 것은 의미없다 생각해서 다음과 같은 프로세스로 진행되는 시스템을 구현하고자 했다.:
1. 멀티스레드를 활용하여 오디오를 수집하는 task, 전사를 수행하는 task를 스레드로 나누어 구현한다.
2. 오디오 스레드에서는 그때그때 녹음한 데이터를 0.5초 ~ 1초 사이의 chunk 단위로 전사를 수행해줄 queue에 쌓아준다.
3. 전사를 수행할 queue에 데이터가 들어오면 바로바로 전사를 수행한다.
4. 말이 다 끝나면 문장 사이 침묵을 감지하면 그때까지 완성된 전사 결과를 한 문장으로 간주하여 이후 번역 task로 넘겨준다.
이렇게까지 해서 코드의 기초를 짰고,
GPT의 도움을 (많이) 받아 콘솔로 확인하는 코드까지 구현할 수 있었다.
코드
main
if __name__ == "__main__":
try:
clear_screen()
t1 = threading.Thread(target=audio_collection_thread)
t2 = threading.Thread(target=stt_processing_thread)
t1.daemon = True
t2.daemon = True
t1.start()
t2.start()
update_captions()
while True:
time.sleep(0.1)
except KeyboardInterrupt:
clear_screen()
print("\n🛑 프로그램 종료...")
time.sleep(0.5)
print("👋 종료 완료")
1번에서 말했듯, 실시간성 구현을 위해 audio_collection_thread 에서는 음성을 수집하고 stt_processing_thread에서는 전사(STT)를 수행하는 함수를 구현해줬다.
프로그램 종료 시 모든 스레드도 그에 따라 task를 종료해주기 위해 daemon 설정을 해주고,
종료되기 전까지 0.1초마다 새로 불러올 수 있게 sleep을 걸어주며 실시간 STT를 수행한다.
stt_processing_thread
# STT 처리 스레드 (OpenAI Whisper API 최신 버전)
def stt_processing_thread():
global current_caption
buffer = np.zeros((0, 1), dtype=np.float32)
max_buffer_size = samplerate * 5
try:
while True:
try:
data = audio_queue.get(timeout=1)
buffer = np.concatenate((buffer, data), axis=0)
if len(buffer) > max_buffer_size:
buffer = buffer[-max_buffer_size:]
chunk_size = int(samplerate * 3.0)
if len(buffer) >= chunk_size:
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
sf.write(f.name, buffer[:chunk_size], samplerate)
audio_file = open(f.name, "rb")
response = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
language="ko"
,
prompt="회의 중입니다. 또박또박 말하는 내용을 받아적어.")
audio_file.close()
os.unlink(f.name)
text = response.text.strip()
if text:
with caption_lock:
if not current_caption or text[0].isupper() or any(current_caption.endswith(p) for p in ['.', '!', '?', '。', '!', '?']):
if current_caption:
caption_history.append(current_caption)
current_caption = text
else:
current_caption += " " + text
update_captions()
buffer = np.zeros((0, 1), dtype=np.float32)
audio_queue.task_done()
except queue.Empty:
continue
except KeyboardInterrupt:
pass
사실 여기서는 침묵을 감지한다기보다 오디오를 계속 열어두면서
(sample rate * 3) 만큼씩, 즉 3초 분량만큼 버퍼 변수(buffer)에 계속 chunk를 쌓은 후 전사를 진행한다. (overflow를 방지하기 위해 max크기는 5초 분량으로 선언을 해놓고, 3초씩만 모아두었다 방사)
전사를 진행하는 방식은
.wav 임시파일을 만들어서 해당 음성을 'whisper-1' 모델에 전달해주고,
text에 모델 response의 text(답변)부분만 저장하고,
임시파일을 지우는 식으로 진행된다.
참쉽죠?
그 아래는 출력을 위해 락걸어놓은 스레드에 접근해서 전사 결과를 기록하는 텍스트를 추가해주는 작업이다.
audio_collection_thread
# 오디오 수집 스레드
def audio_collection_thread():
try:
with sd.InputStream(samplerate=samplerate, channels=1,
callback=audio_callback, blocksize=block_size):
print("🎙️ 실시간 STT 시작 중... 잠시만 기다려주세요.")
while True:
time.sleep(0.1)
except Exception as e:
print(f"오디오 스트림 오류: {e}", file=sys.stderr)
except KeyboardInterrupt:
pass
이건 사실..
그냥 오디오 열어서 기록하는 함수이다.
mac 환경에서 진행했을때는,
sounddevice 찾아주는게 제일 힘들었다
전체 코드
import sounddevice as sd
import numpy as np
from openai import OpenAI
import queue
import threading
import time
import os
import sys
import tempfile
import soundfile as sf
from collections import deque
from dotenv import load_dotenv
load_dotenv()
os.environ["OPEN_API_KEY"] = os.getenv("OPENAI_API_KEY")
# OpenAI Whisper API 클라이언트 생성
client = OpenAI()
# 큐 설정
audio_queue = queue.Queue()
# 오디오 설정
samplerate = 16000
block_size = 4000 # 0.25초 분량
# 자막 관리를 위한 설정
caption_history = deque(maxlen=5) # 최근 5개 문장 저장
current_caption = ""
caption_lock = threading.Lock()
# 오디오 콜백
def audio_callback(indata, frames, time, status):
if status:
print(f"상태: {status}", file=sys.stderr)
audio_queue.put(indata.copy())
# 화면 지우기 함수
def clear_screen():
os.system('cls' if os.name == 'nt' else 'clear')
# 자막 출력 함수
def update_captions():
clear_screen()
print("\n\n\n")
print("=" * 60)
print("🎙️ 실시간 음성 인식 자막 (Ctrl+C로 종료)")
print("=" * 60)
for prev in list(caption_history)[:-1]:
print(f"\033[90m{prev}\033[0m")
if caption_history:
print(list(caption_history)[-1])
if current_caption:
print(f"\033[1m{current_caption}\033[0m", end="▋\n")
else:
print("▋")
print("=" * 60)
# 오디오 수집 스레드
def audio_collection_thread():
try:
with sd.InputStream(samplerate=samplerate, channels=1,
callback=audio_callback, blocksize=block_size):
print("🎙️ 실시간 STT 시작 중... 잠시만 기다려주세요.")
while True:
time.sleep(0.1)
except Exception as e:
print(f"오디오 스트림 오류: {e}", file=sys.stderr)
except KeyboardInterrupt:
pass
# STT 처리 스레드 (OpenAI Whisper API 최신 버전)
def stt_processing_thread():
global current_caption
buffer = np.zeros((0, 1), dtype=np.float32)
max_buffer_size = samplerate * 5
try:
while True:
try:
data = audio_queue.get(timeout=1)
buffer = np.concatenate((buffer, data), axis=0)
if len(buffer) > max_buffer_size:
buffer = buffer[-max_buffer_size:]
chunk_size = int(samplerate * 3.0)
if len(buffer) >= chunk_size:
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
sf.write(f.name, buffer[:chunk_size], samplerate)
audio_file = open(f.name, "rb")
response = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
language="ko"
,
prompt="회의 중입니다. 또박또박 말하는 내용을 받아적어.")
audio_file.close()
os.unlink(f.name)
text = response.text.strip()
if text:
with caption_lock:
if not current_caption or text[0].isupper() or any(current_caption.endswith(p) for p in ['.', '!', '?', '。', '!', '?']):
if current_caption:
caption_history.append(current_caption)
current_caption = text
else:
current_caption += " " + text
update_captions()
buffer = np.zeros((0, 1), dtype=np.float32)
audio_queue.task_done()
except queue.Empty:
continue
except KeyboardInterrupt:
pass
# 메인 실행
if __name__ == "__main__":
try:
clear_screen()
t1 = threading.Thread(target=audio_collection_thread)
t2 = threading.Thread(target=stt_processing_thread)
t1.daemon = True
t2.daemon = True
t1.start()
t2.start()
update_captions()
while True:
time.sleep(0.1)
except KeyboardInterrupt:
clear_screen()
print("\n🛑 프로그램 종료...")
time.sleep(0.5)
print("👋 종료 완료")
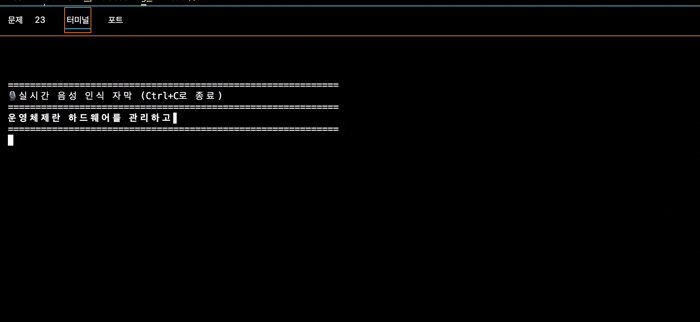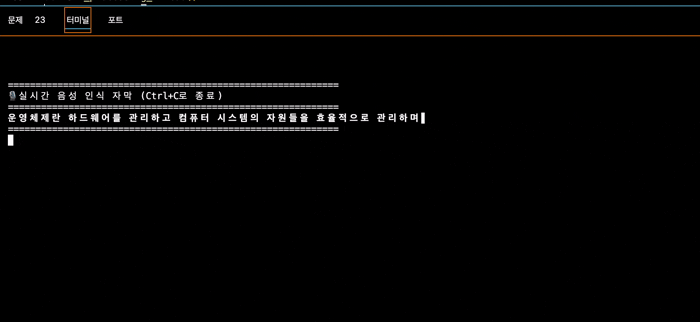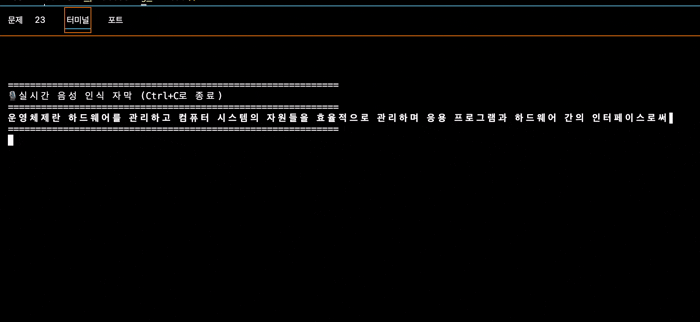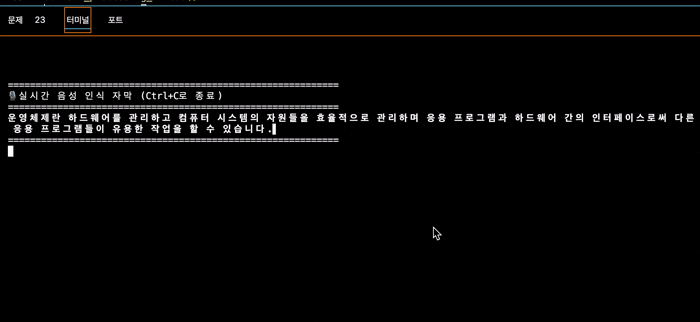
실행 결과

테스트할때 보통 눈에 보이는 아무 공부자료를 보면서 읽는 편인데 😅
운영체제에 대한 글을 읽었을 때의 코드 실행 결과이다.
아무래도 나의 말을 3초 단위로 가져와서 전사를 하기도 하고, 인공지능 모델이라 뒤에 말을 어느정도 예상해서 작성하기도 하여 저렇게 혼자 마무리해버리는 경우도 발생한다.
콘솔 출력은 GPT가 CLI에 예쁘게 보일 수 있게 색상을 입혀서 작성해줬는데,
{prev}와 {current_caption}을 통해 현재 말하는 문장을 구분하여 이전에 처리한 문장은 회색으로 보이게 해줬다.
그러나....
나를 가장 고생시켰던 문제
바로

정적이 길어질 때,
정적을 정적으로 인식하지 않고 소음이 오디오에 캡쳐되면
나는 말한적도 없는 '시청해주셔서 감사합니다.' 와 같은 유튜브와 관련된 랜덤한 문구가 뜬다는 것.
이유는
한국어 음성 모델을 학습할 때 주로 한국어 채널들의 유튜브 - 유튜브 스크립트 쌍으로 학습을 진행했기 때문에 저런 문구가 출력된다는 것..

이후에 테스트할때도 저거때문에 고생 많이했다..ㅠㅠ
해결방법은
이후에 chunk 데이터로부터 일정 frequency 이상의 값만 인식하도록 임계치를 잡아주거나(잘 먹히진 않음),
전사 단계 말고 좀 더 고도화된 모델을 쓰는 번역 단계에서 임의로 전달된 맥락을 파악해서 번역 처리해달라고 프롬프트를 작성하는 방법
등등이 있을 수 있다..
나는 번역단계에서 프롬프트한테 알아서 내용을 쳐내달라고 했었다



